2021. 11. 29. 19:31ㆍ개발/JPA
테이블 구조
지난 포스팅에 이어 @ManyToOne과 @OneToMany에 대해서 예시 코드를 작성한다.
은행 서비스에서 사용자(User)가 1개 이상의 계좌(Account)를 가질수 있다면 아래처럼 물리 테이블을 설계할것이다. TABLE_USER 입장에서 보면 OneToMany이고, TABLE_ACCOUNT 입장에서 보면 ManyToOne이다.

@ManyToOne 단방향
TABLE_ACCOUNT 테이블에 존재하는 user_id 컬럼을 통해 Account Entity에 있는 user 필드의 정보를 채운다.
여러개의 계좌가 사용자 한명에게 사용될수 있으므로 @ManyToOne 어노테이션을 추가한다.
연관관계의 주인임을 나타내고 물리 테이블에 있는 user_id 컬럼을 통해 user 필드를 채우기 위해 @JoinColumn을 작성한다.
User Entity에서는 별다른 코드를 작성하지 않는다.
아래는 실행을 위한 예시 코드이다.
Line 50에서 Account Entity를 통해 사용자의 이름을 조회하는 모습을 확인할 수 있다.
TABLE_ACCOUNT를 조회할때 user_id(PK)를 Join key로 사용해서 TABLE_USER에 있는 사용자 정보를 함께 불러온다.
@ManyToOne 양방향
Account Entity의 user 필드가 관계의 주인이고, User Entity에서 Account Entity 정보를 조회할 수 있도록 하는 양방향 매핑 코드를 작성한다.
양방향 매핑을 위해서 User Entity에 코드를 추가하면 된다.
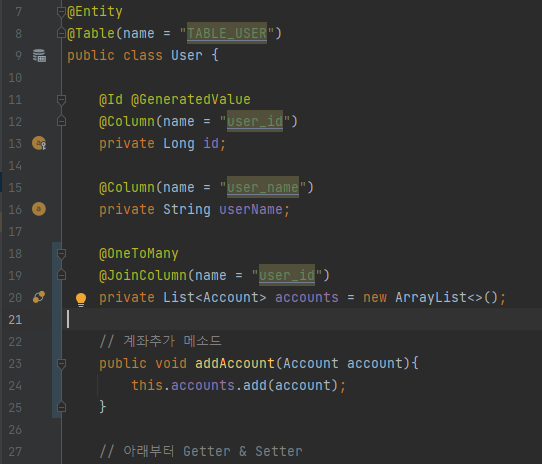
- User Entity는 다수의 Account Entity를 가질수 있기 때문에 List<Account> 형으로 객체를 정의한다.
- 사용자 한명의 여러개의 계좌를 가질수 있으므로 @OneToMany 어노테이션을 추가한다.
- 조회하려는 정보는 Account Entity의 user 정보를 참고할것이기 때문에 mappedBy를 통해 연관관계를 매핑한다. ( 생략하면 실행시 중간 테이블 생성됨!! )
- 계좌 추가의 편의를 위한 addAccount 메소드를 추가한다. Line 22~24 참고

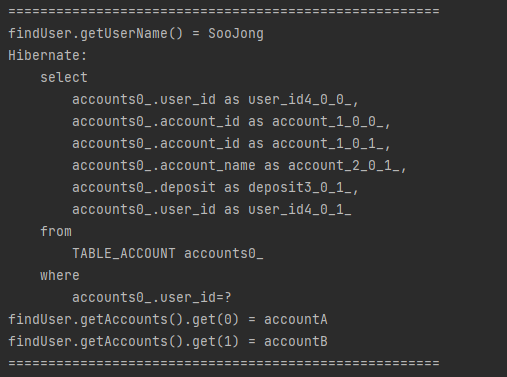
사용자가 보유하고 있는 계좌정보를 조회하는 예시 코드를 작성한다. Line 47~52 참고

하지만 예시 코드를 수행하면 사용자를 통해서 계좌정보를 전혀가져오지 못한다.

물리테이블을 조회해보면 TABLE_ACCOUNT에 user_id 컬럼이 비어 있다.

User Entity의 addAccount 메소드를 통해서 분명히 계좌정보를 사용자에게 할당해줬는데 DB Insert시에는 이 정보가 전혀 반영되지 않았다.


지금까지 작성한 코드를 잘 보면 Account Entity의 user 필드에 값을 셋팅하는 동작이 하나도 없다. addAccount 메소드에선 단지 주입받은 account를 User Entity의 accounts에 추가하는 작업만 할뿐이다.
여기서 accounts는 조회성 필드이므로 여기에 아무리 값을 넣어봤자 물리 테이블에는 반영되지 않는다.
따라서 addAccount메소드에서 입력받은 파라미터인 account의 사용자 정보를 셋팅하는 추가적인 작업이 필요하다. Account Entity에 있는 user 필드는 물리 테이블과 직접 매핑되어 있으므로 값을 변경하면 DB에 반영이 된다!!
Line 24 참고.

예제코드를 수행하면 아래처럼 정상적으로 동작하게 된다.

@OneToMany 단방향
User Entity에 있는 accounts필드를 매핑의 주인으로 하기위해 먼저 @OneToMany 어노테이션을 적용한다.
accounts 필드에 데이터를 채우기 위해선 @JoinColumn 어노테이션을 작성해야하는데 TABLE_USER는 account_id라는 컬럼이 존재하지 않는다. 이 경우 @JoinColumn의 name값은 TABLE_ACCOUNT의 user_id 컬럼으로 작성한다.
이 뜻은 User Entity에 있는 accounts 필드의 데이터를 채울때 TABLE_ACCOUNT의 user_id 컬럼을 통해 데이터를 가져오는걸 의미한다.
※참고 - @ManyToOne에는 mappedBy 옵션이 없기 때문에 @OneToMany가 관계의 주인일 경우 양방향 매핑이 불가능하다. ( = @ManyToOne은 항상 주인이 된다. )
Account Entity에는 user 필드를 지운다. ( User Entity에서 TABLE_ACCOUNT의 user_id 컬럼을 관리하게 된다. )

위 구조는 딱봐도 뭔가 모양이 이상하다. 물리 테이블을 보면 TABLE_ACCOUNT에 user_id 컬럼이 있다. 하지만 Account Entity를 보면 user_id와 매핑되는 정보가 없고, 오히려 User Entity에서 TABLE_ACCOUNT의 user_id를 관리한다. 소스코드상에 있는 Entity의 필드와 물리테이블에 존재하는 컬럼간의 짝(?)이 전혀 맞지 않는다.

이렇게 연관관계 매핑이 된다면 User Entity의 accounts 필드의 정보를 변경하게 된다면 ( 사용자가 보유한 계좌정보가 변경될때 ) TABLE_USER의 쿼리문이 아닌 TABLE_ACCOUNT에 대한 쿼리문이 나가게된다. 가능하면 User Entity의 내용이 수정되었을땐 TABLE_USER가 중심이 되는 쿼리가 나가는게 좀더 명확하고 이해하기에도 쉽다. 따라서 가능하면 연관관계의 주인은 @ManyToOne이 되도록하자.
아래와 같이 사용자의 계좌를 추가하는 예제코드를 작성한다.

Line 34에서 User Entity의 데이터를 수정했는데 TABLE_ACCOUNT 테이블과 관련된 테이블이 update되는 모습을 확인할 수 있다.

'개발 > JPA' 카테고리의 다른 글
| [JPA] mappedBy 이해하기 (0) | 2021.11.16 |
|---|---|
| [JPA] 단방향 @OneToOne , @JoinColumn (0) | 2021.11.11 |