2021. 5. 22. 14:08ㆍ개발/Kafka
Confluent에서 제공하는 JDBC Connector를 사용하기 위해 아래 사이트로 접속한다.
Confluent Hub Client | Confluent Documentation
Confluent Hub Client The Confluent Hub client is a command line tool that makes it easy to install and update components from Confluent Hub into a local Confluent Platform installation. Installing Confluent Hub Client The Confluent Hub client is natively i
docs.confluent.io
라이센스는 Confluent Community License를 따르는데 요약하자면 무료 라이센스.

Confluent Hub Client 설치하기
Confluent에서 제공하는 JDBC Connector를 다운로드 받기 위해선 2가지 방법이 있다.
첫번째는 Confluent Hub Client(CLI)를 사용하는방법이고, 두번째는 위 사진에서도 알수 있듯이 사이트에서 직접 받는 방법이다.
이번 포스트에선 Confluent Hub를 사용해 본다. Confluent Hub를 다운로드 받기 위해서 아래 사이트에 접속한다.
Confluent Hub Client | Confluent Documentation
Confluent Hub Client The Confluent Hub client is a command line tool that makes it easy to install and update components from Confluent Hub into a local Confluent Platform installation. Installing Confluent Hub Client The Confluent Hub client is natively i
docs.confluent.io
Ubuntu 20.04 LTS를 사용하기 때문에 Linux아래에 있는 링크로 다운로드를 진행했다.
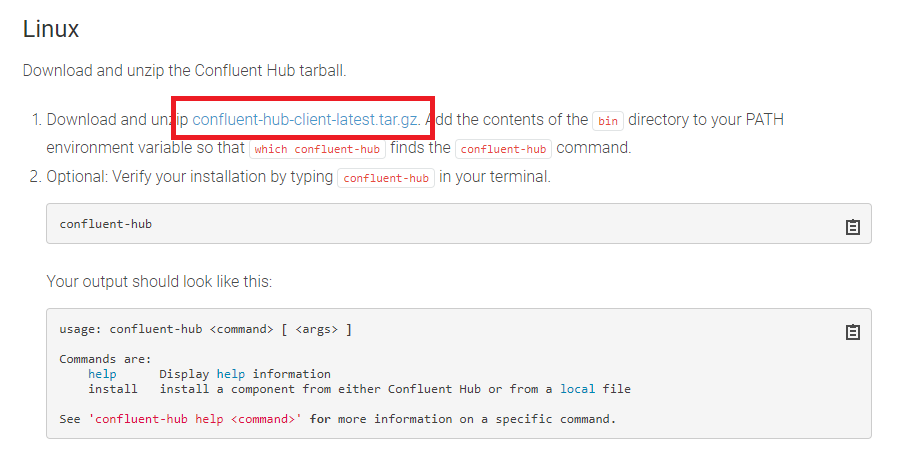
다운받은 파일을 압축해제한다.

Confluent-hub 명령어를 사용하기 위해 PATH환경변수에 압축해제한 bin폴더의 경로를 추가해준다.


JDBC Connector 설치하기
이제 사이트에서 제공한 명령어를 이용해서 jdbc-Connector를 설치해보자.
confluent-hub install confluentinc/kafka-connect-jdbc:10.2.0
하지만 다음과 같은 에러가 발생한다. 에러로그를 보니 --component-dir과 --worker-configs를 작성하라고한다.

따라서 component-dir를 위해 connect라는 폴더를 만들었으며, 그안에 worker-configs를 위한 worker.properties 문서를 하나 만들었다. ( worker.properties에는 아무것도 작성하지 않음 )

경로를 추가한 명령어를 실행해본다.
confluent-hub install confluentinc/kafka-connect-jdbc:10.2.0 --component-dir /home/soojong2/connect --worker-configs /home/soojong2/connect/worker.properties
성공적으로 설치가 완료되었다면 아래와 같은 로그를 확인할 수 있다.

처음에는 경로만 지정해주면 되는줄 알고 명령어를 실행했는데 그렇게하면 에러가 발생한다. 따라서 수정가능한 파일, 폴더를 만들어두고 다운로드 명령어를 실행하도록하자.

다운로드가 완료되었다면 worker.properties를 확인해보자. 설치하는 과정에서 자동으로 plugin.path를 작성되었다.

그리고 connect폴더에는 confluentinc-kafka-connect-jdbc생성되는데 하위의 lib폴더를 보면 JDBC Connect를 위한 jar파일들이 있다.

설정파일 작성
worker.properties 파일에 추가적인 설정을 셋팅한다 ( Apache Kafka를 다운받으면 config폴더안에 connect-distributed.properties라는 폴더가 있는데 해당 파일을 참고해서 작성했다. )
아래는 수정한 worker.properties이다. 해당 설정을 바탕으로 connect 서버를 구동한다.

- bootstrap.servers : Kafka Server의 주소. 복수개의 Kafka Server로 클러스터를 구성한 경우 콤마(,)를 이용해 작성한다.
- key.converter : Key connect data를 위한 Converter이다. 여기에 정의된 클래스를 이용해 Source Connector 또는 Sink Connector에 어떤 데이터 포맷을 셋팅한다. ( Kafka에 key,value형태로 데이터를 제공하기 때문에 key,value 컨버터가 각각 존재한다. )
- value.converter : 위 와 동일한의미이며 Value connect data를 위한 Converter이다. 주로 Avro와 JSON을 많이 이용한다고 한다.
- key.converter.schemas.enable : key 컨버터를 사용하기 위해서 true로 셋팅한다.
- value.converter.schemas.enable : value 컨버터를 사용하기 위해서 true로 셋팅한다.
- offset.storage.topic : Connector와 Task의 configuration offset이 저장될 Topic의 이름.
- offset.storage.replication.factor : 위 Topic의 개수
- config.storage.topic : Connector와 Task의 configuration data가 저장될 Topic의 이름
- config.storage.replication.factor : 위 Topic의 개수
- status.storage.topic : Connector와 Task의 상태변경에 대한 정보가 저장될 Topic이름
- status.storage.replication.factor : 위 Topic의 개수
- offset.flush.interval.ms : task offset의 commit 요청 간격시간. 10초에 한번씩 task의 offset을 commit하도록 셋팅했다.
connector 실행
worker.properties 셋팅을 마무리 했다면 Kafka Connect를 실행한다. 실행을 위한 shell 파일은 Apache Kafka 설치시 bin폴더에 들어있는 connect-distributed.sh를 사용한다. 분산모드의 경우 파라미터로 Connect설정 파일 하나만 셋팅하면된다.
./bin/connect-distributed.sh /home/soojong2/connect/worker.properties
실행에 성공하면 아래와같은 로그를 확인할 수 있다.

이번 포스팅은 여기서 마무리하고 다음 포스팅에서 Source Connector에 대해 공부한 내용을 작성하겠습니다.
참고 사이트
Worker Configuration Properties | Confluent Documentation
Worker Configuration Properties The following lists many of the configuration properties related to Connect workers. The first section lists common properties that can be set in either standalone or distributed mode. These control basic functionality like
docs.confluent.io
Schema Registry Overview | Confluent Documentation
Schema Registry Overview Confluent Schema Registry provides a serving layer for your metadata. It provides a RESTful interface for storing and retrieving your Avro®, JSON Schema, and Protobuf schemas. It stores a versioned history of all schemas based on
docs.confluent.io
'개발 > Kafka' 카테고리의 다른 글
| Source Connector Offset 초기화 하기 (0) | 2021.05.27 |
|---|---|
| Source Connector 생성 하기 ( feat. Topic 자동생성 ) (0) | 2021.05.22 |
| Confluent의 Kafka Connect Concept (0) | 2021.05.17 |
| [Kafka] 순서보장 ( Producer 2개와 Consumer 1개 예시 ) (0) | 2021.05.05 |
| ZooKeeper 살펴보기 ( feat. Kafka 조금... ) (0) | 2021.05.02 |