2021. 5. 27. 10:36ㆍ개발/Kafka
이전에 게시글을 작성하면서 Source Connector에서 특징을 발견했다. ( Source Connector의 모드는 Increment )
Source Connector 생성 하기 ( feat. Topic 자동생성 )
Kafka Connect는 하나의 서비스 형태로 구동되기 때문에 REST방식의 Connector 관리가 가능하다. worker 설정파일에 별다른 셋팅을 하지 않았다면 8083포트를 통해서 Connector 생성 요청이 가능하다. REST방식
soojong.tistory.com
Source Connector를 Delete하고 똑같은 이름의 Source Connector를 생성하는 작업을 수행했었다. Connector의 이름이 같긴하지만 Delete를 하고 새로운 Source Connector를 만들었기때문에 당연히 테이블의 첫번째 row부터 읽어올줄 알았는데 새롭게 추가된 row만 읽어왔다.
1. 현상 재연
Source Connector 설정을 작성한다. Source Connector의 이름은 jdbc_source_connector이다.
Source Database의 user 테이블에서 발생한 데이터를 읽어 Topic으로 Pub하도록 셋팅한다.

분산모드의 Worker의 경우 REST API 형태로 Connector 관리를 제공한다. POST를 요청을 통해 Connector를 생성한다.

Source DB의 user Table

user 테이블에 3개의 data를 Insert했다.
INSERT INTO user VALUES( 1 , 'Mark' , '20' , 'seoul');
INSERT INTO user VALUES( 2 , 'John' , '23' , 'seoul');
INSERT INTO user VALUES( 3, 'Kim' , '31' , 'seoul');
Source Connector가 user Table에 데이터가 Insert 되었음을 인지한다. Source Connector내부에 존재하는 Task가 jdbc-connector-user라는 이름을 가진 Topic으로 record를 보내려고 한다는 로그를 확인할 수 있다.

Source Connector가 3개의 row를 Topic에 성공적 보냈지 확인하기 위해 Consumer를 실행한다.

여기서 DELETE 요청을 통해 Source Connector를 삭제한다.

Worker의 log를 통해 성공적으로 삭제되었음을 확인할 수 있다.

이제 다시 Source Connector를 생성한다. 하지만 Worker의 로그를 확인해보면 여전히 flushing할 데이터가 없다고 나온다. 3개의 데이터를 지우고 다시 3개를 Insert해도 현상은 똑같았다.
Topic에 들어온 새로운 데이터가 없기때문에 Consumer도 아무 변화가 없다.

1건의 데이터를 Insert해보자.
INSERT INTO user VALUES( 4 , 'Park' , '33' , 'seoul');
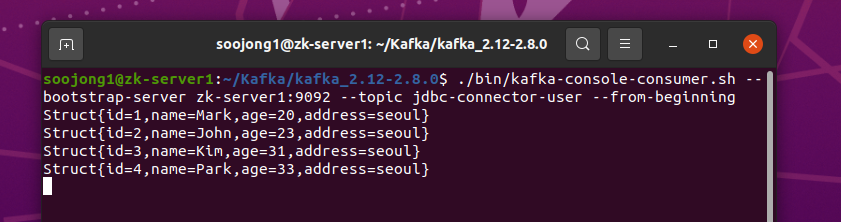
Source Connector가 4번째 데이터가 Insert되었음을 인식하고 Topic으로 넘겨준다.
여기서 알 수 있었던 것은 jdbc-connector-user라는 이름을 가진 Source Connector는 user 테이블에 4번째 데이터가 들어오기만을 기다리고 있지 1, 2, 3번 row에선 무슨일이 있는지는 전혀 관심이 없다는것이다. 그리고 Source Connector를 삭제 하고 재생성을 해도 이 정보는 유지가 된다.

Consumer는 Topic의 데이터를 읽어 출력한다.
Source Connector를 분명히 제거하고 다시 생성했음에도 이전의 Table Offset을 기억하고 있는 모습이다. Source Connector를 삭제 후 똑같은 이름을 가진 Source Connector를 재생성해도 Table Offset을 유지하고 있는점이 장점이 될수 있다.( Connector의 설정을 변경해야할 경우 Delete후 재생성해야한다. 그때 Table Offset에 대한 작업을 추가로 해줄 필요가 없다. ) 하지만 데이터 양에 따른 Source Connector의 성능 측정을 할때는 Table Offset을 초기화해야하는 경우가 필요하다.
2. 해결
구글해보니 해결법은 크게 두가지가 있었다.
첫번째는 가장 쉬운 방법으로써 Source Connector의 이름을 변경하는 방법이다. 예제에서 Source Connector 이름을 jdbc_source_connector로 했는데 jdbc_source_connector1같이 다른 이름으로 설정하라는 것.
두번째는 직접 Source Connector 의 Table Offset을 수정하는 방법이다.
먼저 kafkacat을 다운로드한다. kafkacat은 kafka 브로커에 대한 정보를 조회 및 수정할 수 있도록 해준다.

사실 Worker서버를 구동하면 아래 형광색 표시한 3개의 Topic이 자동으로 생성된다. 여기서 connect-offsets이라는 Topic이 Connector의 Table Offset을 관리하는 역할을 한다.

kafkacat을 통해서 해당 Topic을 한번 확인해보자.
kafkacat -b zk-server1:9092 -t connect-offsets -C -K#
- -b zk-server1:9092 : 접근할 Broker Server는 zk-server1:9092이다.
- -t connect-offsets: 접근할 Topic의 이름은 connect-offsets이다.
- -C : Consumer인 상태로 접근한다( Topic을 Subscribe할 수 있다. )
- -K# : Topic이 가지고 있는 데이터의 Key와 Message를 입력된 Delimeter인 #을 통해 나눠서 출력해준다.

노란색 형광색 칠된부분을보면 중간에 #이 들어가 있는 문자열을 확인할 수 있다.( 위쪽에 2개정도 보이는데 이전에 작업한 내용이 남아 있는것이니 무시한다. )
Reached end of topic connect-offsets [1] at offset 0의 뜻은 "Partition 1번을 처음부터 읽었는데 offset 0에 도달했다"는 것을 의미한다.
["jdbc_source_connector",{"protocol":"1","table":"mydatabase.user"}]#{"incrementing":4}의 뜻은 #을 기준으로 좌측이 메세지의 Key, 우측이 Value를 의미한다. Key를 보면 Connector의 이름, 관리하고 있는 table 정보를 알 수 있다. Value를 보면 incrementing 정보를 확인할 수 있다.
-f 옵션을 사용해서 좀더 자세하게 Topic의 내용을 확인해보자.
kafkacat -b zk-server1:9092 -t connect-offsets -C -f '\n Key (%K bytes): %k \n Value (%S bytes): %s \n Timestamp: %T \n Partition: %p \n Offset: %o\n'
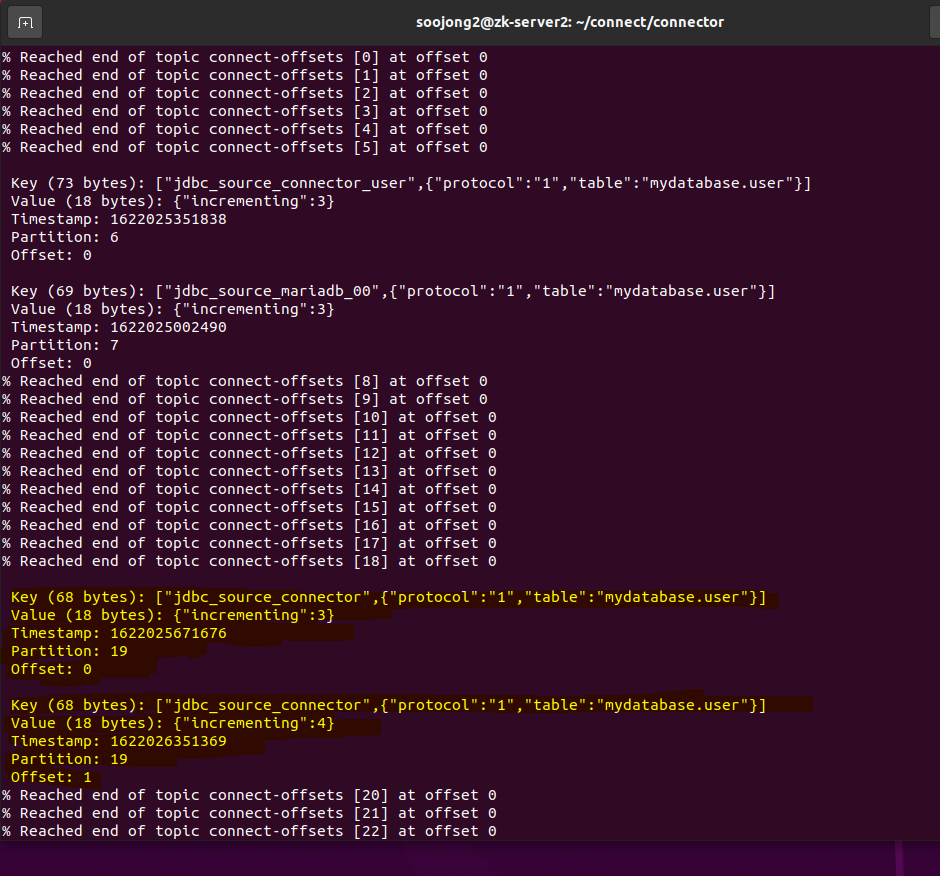
형광색으로 표시한 부분을 보면 Partition 19번의 0번째 Offset에는 Incrementing : 3이 있고 , 1번째 Offset에는 incrementing : 4가 있는모습을 확인해볼 수 있다. 즉, Partition 19번에는 2개의 메세지가 들어있으며 0번째(Offset 0)의 Value는 Incrementing : 3이고, 1번째(Offset 1)이자 가장 최신의 메세지의 Value는 Incrementing :4 이다.
19번 Partition에서 jdbc_source_connector의 incrementing 정보를 관리한다는것을 기억하고 다음으로 넘어간다.
이제 할것은 Partition 19번에 Incrementing 정보가 없는 데이터를 Pub하는것이다.
kafkacat의 Producer 모드를 통해서 데이터를 Publish할 수 있다.
echo '["jdbc_source_connector",{"protocol":"1","table":"mydatabase.user"}]#' | kafkacat -b zk-server1:9092 -t connect-offsets -P -Z -K# -p 19
- -P : Producer 모드로 접근한다.
- -Z : value에 NULL 정보를 셋팅한다.
- -K# : Key와 Value를 #이라는 Delimeter를 통해 구분한다.
- -p : 파티션 번호
- echo를 통해 발행할 메세지를 작성한다. #을 통해 Key와 Message를 구분하기로 했기때문에 Key만 작성하고 #의 오른쪽의 Value정보를 제공하지 않는다.
위 명령어를 수행하고 connect-offsets Topic정보를 다시 조회해보면 19번 Partition에 새로운 메세지가 Pub되었다는걸 확인할 수 있다. Offset이 1 증가해서 2가 되었다. 새롭게 입력된 정보는 Value가 비어있다.

이제 다시 Source Connector를 생성해보자. 이전과 Source Connector의 이름이 똑같다.

Source Connector가 생성됨과 동시에 Partition 19번에서 가장 최근 Offset을 가져올것이고 해당 Offset은 2였으며, Value에는 Incrementing 정보가 없다. 따라서 처음부터 table의 데이터를 가져오게 된다.

실행중인 Consumer를 확인해보자. Source Connector가 처음부터 데이터를 읽어서 Topic에 넣어줬기 때문에 Consumer에서 형광색 표시한 4개의 Message를 출력한다

참고 사이트
Reset Kafka Connect Source Connector Offsets
rmoff.net
How do we reset the state associated with a Kafka Connect source connector?
We are working with Kafka Connect 2.5. We are using the Confluent JDBC source connector (although I think this question is mostly agnostic to the connector type) and are consuming some data from an...
stackoverflow.com
Kafka Socket server failed - Bind Exception - Cloudera Community
'개발 > Kafka' 카테고리의 다른 글
| [Kafka] Consumer의 3가지 수신 방법 + Segment 삭제 (0) | 2022.03.28 |
|---|---|
| [Kafka] Producer의 3가지 전송 방법 Java로 구현해보기 (0) | 2022.03.24 |
| Source Connector 생성 하기 ( feat. Topic 자동생성 ) (0) | 2021.05.22 |
| Confluent Hub Client설치, JDBC Connector 구동 (0) | 2021.05.22 |
| Confluent의 Kafka Connect Concept (0) | 2021.05.17 |