2022. 3. 28. 23:00ㆍ개발/Kafka
지난 시간에 이어 이번엔 Consumer를 Java로 구현해본다.
Segment 삭제
peter-basic01을 Consume하면 Topic에 존재하는 모든 레코드가 출력된다. 이전 포스트에서 peter-basic01로 3건의 Record를 보냈기 때문에 새로운 Consumer가 Partition의 0번째 offset부터 모두 읽어오는 모습이다. 원할한 테스트를 위해서 Partition에 있는 레코드를 모두 지워보도록 하자.

Topic에 있는 Partition으로 레코드가 들어오면 Segment라는 파일에 저장된다. Segment 확인을 위해서 /data/kafka-logs 경로로 이동한다.
이전에 peter-basic01 Topic을 생성했기 때문에 peter-basic01-0 디렉토리가 존재하는것을 확인할 수 있다. 이름 끝에 있는 0은 Topic에 있는 Parition번호를 의미한다. Topic을 만들때 Partition의 개수를 1로 설정했기때문에 peter-basic01-0 디렉토리만 존재한다.
peter-basic01-0 디렉토리로 이동해서 log 확장자를 가진 파일을 16진수로 조회하면 그동안 Partition이 수신한 레코드를 확인할 수 있다.
/usr/local/kafka/bin/kafka-configs.sh --bootstrap-server peter-kafka01.foo.bar:9092 --topic peter-basic01 --add-config retention.ms=0 --alter 명령어를 사용해서 Segment 보관시간을 0으로 변경한다. (설정 반영은 약 5분정도 걸린다.)
이제부터 peter-basic01 Topic에 레코드가 들어올때 0초마다 Segment를 제거한다.
다시 peter-basic01-0 디렉토리의 파일을 확인해보면 아래와 같이 파일명이 변경된것을 확인할 수 있다. Segment 보관 주기가 만료된 파일은 삭제되고 새로운 Segment 파일이 생성되었다. 새로운 Segment 파일은 Partition내 offset 번호로 생성되며, 내용은 비어있다. ( offset은 마지막까지 읽은 위치가 아니라 다음으로 읽어야 할 위치를 값으로 가진다. )
/usr/local/kafka/bin/kafka-configs.sh --bootstrap-server peter-kafka01.foo.bar:9092 --topic peter-basic01 --delete-config retention.ms --alter 명령어를 통해서 Segment 보관주기를 default로 변경한다. ( default는 7일이다. )
Auto Commit 방식의 Consumer
Producer와 마찬가지로 Properties 타입 인스턴스에 Consumer에 대한 설정을 세팅한다.
group.id는 생성한 Consumer가 속할 Consumer Group의 ID를 의미한다.
enable.auto.commit은 Partition의 offset을 자동으로 commit하도록 하는 옵션이다. true로 셋팅하면 Consumer가 commit요청을 보내지 않아도 자동으로 offset이 commit 된다.
auto.offset.reset은 Consumer에 대한 offset을 찾지 못한경우 어느 offset으로 초기 설정할지 결정하는 옵션이다. latest는 가장 마지막의 offset을 사용하도록 한다.
package com.soojong.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
import java.time.Duration;
public class ConsumerAuto {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers","peter-kafka01.foo.bar:9092,peter-kafka02.foo.bar:9092,peter-kafka02.foo.bar:9092");
props.put("group.id", "peter-consumer01"); // 컨슈머 그룹
props.put("enable.auto.commit","true"); // offset을 자동으로 commit하도록 함.
props.put("auto.offset.reset","latest"); // offset이 없는경우는 가장 마지막의 오프셋값으로 설정
props.put("key.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("peter-basic01")); // Consumer가 구독할 Topic을 지정한다.
try {
while(true){
// poll(long)은 2.0버전이후 Deprecated, Duration을 사용해야한다.
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Topic : %s , Partition : %d , Offset : %d, Key : %s, Value :%s\n",
record.topic(),record.partition(),record.offset(),record.key(),record.value());
}
}
} catch (Exception e){
e.printStackTrace();
}finally {
consumer.close();
}
}
}
코드가 정상적으로 구동되는지 확인한다.
동기(Synchronous) 방식 Consumer
Auto commit 예제에선 Polling과 동시에 자동으로 Offset을 Commit 했지만, 이번 코드에선 enable.auto.commit을 false로 설정함으로써 자동 Commit이 되지 않도록 했다.
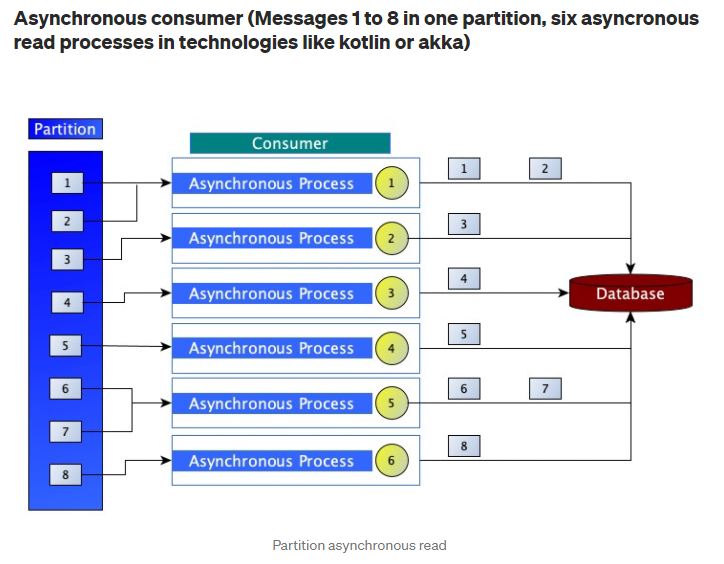
Polling한 Record들을 출력한 후에 offset을 Commit 하도록 했다. ( consumer.commitSync() 코드 추가 )
동기방식은 속도면에선 느리겠지만 메시지 손실은 거의 발생하지 않는다. 따라서 중요한 데이터를 Polling 해야할때는 동기방식을 사용하도록 하자.
package com.soojong.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
import java.time.Duration;
public class ConsumerSync {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers","peter-kafka01.foo.bar:9092,peter-kafka02.foo.bar:9092,peter-kafka02.foo.bar:9092");
props.put("group.id", "peter-consumer01"); // 컨슈머 그룹
props.put("enable.auto.commit","false"); // offset 자동 commit을 하지않도록 설정
props.put("auto.offset.reset","latest"); // offset이 없는경우는 가장 마지막의 오프셋값으로 설정
props.put("key.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("peter-basic01")); // Consumer가 구독할 Topic을 지정한다.
try {
while(true){
// poll(long)은 2.0버전이후 Deprecated, Duration을 사용해야한다.
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Topic : %s , Partition : %d , Offset : %d, Key : %s, Value :%s\n",
record.topic(),record.partition(),record.offset(),record.key(),record.value());
}
// 추가 polling 전에 offset을 commit한다
consumer.commitSync();
}
} catch (Exception e){
e.printStackTrace();
}finally {
consumer.close();
}
}
}
정상적으로 구동되는지 확인한다.

비동기(Asynchronous) 방식 Consumer
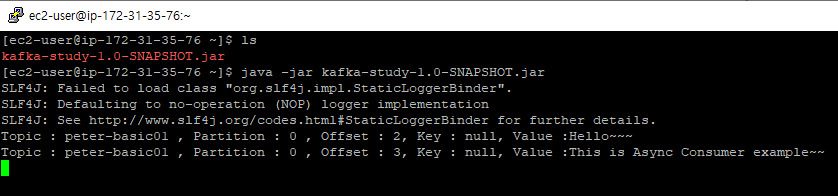
비동기 방식 Consumer 코드는 동기방식의 consumer.commitSync()가 consumer.commitAsync()로 변경된것 밖에 없다.
비동기 방식도 마찬가지로 Polling한 Record들에 대한 작업을 수행하고 나서 Offset을 Commit한다. 여기서 드는 의문은
'동기방식과 차이점이 무엇이냐?' 하는건데 코드로만 보면 별 차이가 없어보인다.
package com.soojong.kafka;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.util.Arrays;
import java.util.Properties;
import java.time.Duration;
public class ConsumerAsync {
public static void main(String[] args) {
Properties props = new Properties();
props.put("bootstrap.servers","peter-kafka01.foo.bar:9092,peter-kafka02.foo.bar:9092,peter-kafka02.foo.bar:9092");
props.put("group.id", "peter-consumer01"); // 컨슈머 그룹
props.put("enable.auto.commit","false"); // offset 자동 commit을 하지않도록 설정
props.put("auto.offset.reset","latest"); // offset이 없는경우는 가장 마지막의 오프셋값으로 설정
props.put("key.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer");
props.put("value.deserializer" , "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("peter-basic01")); // Consumer가 구독할 Topic을 지정한다.
try {
while(true){
// poll(long)은 2.0버전이후 Deprecated, Duration을 사용해야한다.
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(1000));
for (ConsumerRecord<String, String> record : records) {
System.out.printf("Topic : %s , Partition : %d , Offset : %d, Key : %s, Value :%s\n",
record.topic(),record.partition(),record.offset(),record.key(),record.value());
}
// 추가 polling 전에 offset을 commit한다
consumer.commitAsync();
}
} catch (Exception e){
e.printStackTrace();
}finally {
consumer.close();
}
}
}
이 둘의 차이점에 대해 잘 설명한 게시글이 있어 공유한다.
Kafka Asynchronous consumers
Background
suchakjani.medium.com
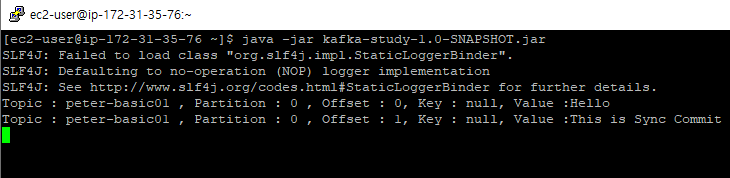
동기방식의 경우 Consumer에 있는 프로세가 Partition에 있는 Record를 차례로 읽어온다. 하지만 비동기 방식의 경우 Consumer에서 다수의 프로세스를 만들어 Partition을 순서에 상관없이 읽어온다. ( Polling Duration이 1초라면 1초동안 가져올 Records를 순서에 상관없이 가져온다. ) 이러한 특성 때문에 비동기 방식은
비동기 방식에서 조심해야할 점이 있다. 만약 Offset 8번이 Polling을 성공하고, 1~7번 Offset을 읽어오는 프로세스 중 하나가 실패하더라도 Consumer는 1~8의 Record를 정상적으로 Polling했다고 판단한다. 여기서 드는 의문이 "비동기 방식은 왜 실패한 프로세스에 대해서 Polling을 재시도 하지 않는가"인데, 만약 3번 Record를 읽는과정에서 에러가 발생했을때 재시도후 Offset을 Commit하게 되면 Consumer의 최신 Offset은 3이 된다. 이때 Polling을 다시 요청하게 되면 3번부터 시작하게 되면 3번부터 8번까지 데이터 중복이 발생할 수 있으므로 비동기 방식은 실패에 대해서 Polling을 재시도 하지 않는다.

코드가 정상적으로 구동되는지 확인한다.
참고 사이트
Kafka Asynchronous consumers
Background
suchakjani.medium.com
'개발 > Kafka' 카테고리의 다른 글
| [Kafka] Producer의 3가지 전송 방법 Java로 구현해보기 (0) | 2022.03.24 |
|---|---|
| Source Connector Offset 초기화 하기 (0) | 2021.05.27 |
| Source Connector 생성 하기 ( feat. Topic 자동생성 ) (0) | 2021.05.22 |
| Confluent Hub Client설치, JDBC Connector 구동 (0) | 2021.05.22 |
| Confluent의 Kafka Connect Concept (0) | 2021.05.17 |